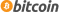- Wat is een regressie analyse precies?
- Wanneer gebruik je een regressie analyse?
- Belangrijke termen binnen regressie analyse
- Soorten regressie analyse
- Hoe voer je een regressie analyse uit?
- Hoe interpreteer je de resultaten van een regressie analyse?
- Hoe rapporteer je een regressie analyse?
- Veelgemaakte fouten bij regressie analyse
- Hulp nodig bij statistiek of regressie analyse?
- Veelgestelde vragen
- Gratis adviesgesprek aanvragen
 Scriptie schrijven? Wij staan voor je klaar!
Scriptie schrijven? Wij staan voor je klaar!Aantekening van de auteur: veel studenten lopen vast bij statistiek en regressie analyse: begrippen zijn abstract, software is verwarrend en fouten liggen snel op de loer. Met deze pagina wil ik je stap voor stap helder inzicht geven, zodat je begrijpt wat je doet, betere keuzes maakt en met vertrouwen aan je scriptie werkt.
Fieldresearch levert je vaak een berg data op – maar wat is fieldresearch precies en hoe vertaal je die resultaten naar een sterke analyse? Op deze pagina ontdek je hoe regressieanalyse je helpt om verbanden te testen en conclusies scherp te onderbouwen. Handig als je vastloopt in statistiek, of als je overweegt je scriptie laten schrijven.
Uit onze artikel leer je:
- Heldere uitleg van regressieanalyse (zonder jargon)
- Overzicht van de belangrijkste soorten + voorbeelden
- Stappenplan: van data tot interpretatie en rapportage
- Valkuilen en tips om fouten te voorkomen.
Regressieanalyse is een statistische methode om het verband tussen een afhankelijke (uitkomst)variabele en één of meer onafhankelijke (verklarende) variabelen te modelleren. Ze schat de grootte en richting van effecten en helpt uitkomsten te voorspellen, terwijl je andere factoren constant houdt. Zo kun je hypothesen onderbouwen met data.
Een regressieanalyse is geschikt wanneer relaties tussen variabelen begrepen of voorspeld moeten worden. Dat komt vaak voor in statistisch onderzoek, scripties en praktijkcases. Toepassing is logisch in situaties zoals:
Bij het begrijpen en correct toepassen van regressie analyse is kennis van de belangrijkste begrippen essentieel. Deze termen komen terug in vrijwel elke statistische analyse en vormen de basis voor het interpreteren van resultaten. Voor studenten helpt een goed begrip hiervan om fouten te voorkomen en conclusies beter te onderbouwen. Hieronder vind je de kernbegrippen helder uitgelegd.
| Term | Definitie |
|---|---|
| Afhankelijke en onafhankelijke variabelen | De afhankelijke variabele is wat je wilt verklaren of voorspellen. De onafhankelijke variabelen zijn de factoren waarvan je verwacht dat ze invloed hebben op de afhankelijke variabele. |
| Relaties | Dit beschrijft hoe sterk en in welke richting variabelen samenhangen. Een relatie kan positief, negatief of afwezig zijn. |
| Residuen | Residuen zijn de afwijkingen tussen de geobserveerde waarden en de waarden die door het regressiemodel worden voorspeld. Ze geven aan hoe goed het model past. |
| Outliers | Outliers zijn extreme waarnemingen die sterk afwijken van de rest van de data en de regressieanalyse kunnen vertekenen. |
| Multicollineariteit | Dit ontstaat wanneer onafhankelijke variabelen sterk met elkaar samenhangen, waardoor het lastig wordt om hun afzonderlijke effect te bepalen. |
| Heteroscedasticiteit en homoscedasticiteit | Bij homoscedasticiteit hebben residuen een constante spreiding. Heteroscedasticiteit betekent dat deze spreiding varieert, wat de betrouwbaarheid van de analyse kan beïnvloeden. |
Regressieanalyse kent verschillende vormen, elk passend bij een specifiek type onderzoeksvraag en dataset. Binnen onderzoeksmethoden voor je scriptie is het belangrijk om te bepalen welke regressievorm aansluit op het onderzoeksdoel en welke assumpties daarbij horen. Hieronder staan de meest gebruikte soorten regressieanalyse, overzichtelijk uitgelegd met korte voorbeelden.
Lineaire regressie analyse
Lineaire regressie analyse wordt gebruikt om een lineair verband te beschrijven tussen een afhankelijke variabele en één of meerdere onafhankelijke variabelen. Het model gaat uit van een regressielijn die het verband tussen de variabelen zo goed mogelijk weergeeft.
Voorbeeld: je onderzoekt of het aantal studie-uren invloed heeft op het tentamencijfer. Hoe meer uren, hoe hoger het cijfer, volgens een lineair patroon.
Enkelvoudige regressie
Bij enkelvoudige lineaire regressie analyse werk je met één onafhankelijke variabele en één afhankelijke variabele. Het is de meest eenvoudige vorm van regressie analyse en wordt vaak gebruikt in introductiecursussen statistiek.
Voorbeeld: je analyseert of leeftijd invloed heeft op het maandelijkse inkomen van studenten met een bijbaan.
Meervoudige regressie analyse
Meervoudige regressie analyse breidt de enkelvoudige variant uit met meerdere onafhankelijke variabelen. Dit maakt het mogelijk om complexere situaties te analyseren en effecten te controleren.
Voorbeeld: je onderzoekt het effect van studie-uren, aanwezigheid bij colleges en voorkennis op het eindcijfer van een vak.
Niet-lineaire regressie
Niet-lineaire regressie analyse gebruik je wanneer de relatie tussen variabelen geen rechte lijn volgt, maar bijvoorbeeld een kromme of exponentiële vorm heeft. Lineaire modellen zijn dan niet geschikt.
Voorbeeld: je analyseert leerprestaties die snel stijgen in het begin, maar na verloop van tijd afvlakken bij extra studietijd.
Logistische regressie analyse
Logistische regressie analyse wordt toegepast wanneer de afhankelijke variabele binair is, zoals ja of nee, geslaagd of gezakt. De uitkomst is een kans in plaats van een exacte waarde.
Voorbeeld: je voorspelt de kans dat een student een tentamen haalt op basis van aanwezigheid en oefenopgaven.
Multivariate regressie analyse
Bij multivariate regressie analyse heb je meerdere afhankelijke variabelen die tegelijk worden geanalyseerd. Dit wordt gebruikt wanneer uitkomsten met elkaar samenhangen.
Voorbeeld: je onderzoekt tegelijk het effect van studiemotivatie op zowel studieprestaties als studie-uitval.
Ridge regression
Ridge regression is een uitbreiding op meervoudige regressie analyse en wordt gebruikt wanneer multicollineariteit een probleem vormt. Het model voegt een straf toe aan grote coëfficiënten.
Voorbeeld: je analyseert economische data waarbij meerdere sterk samenhangende variabelen, zoals inkomen en opleidingsniveau, worden gebruikt.
Lasso regression
Lasso regression lijkt op ridge regression, maar kan variabelen volledig uitsluiten. Dit maakt het model eenvoudiger en beter interpreteerbaar.
Voorbeeld: je selecteert automatisch de belangrijkste factoren die studiesucces voorspellen uit een grote dataset.
Een regressie-analyse uitvoeren hoeft niet ingewikkeld te zijn, zolang je gestructureerd werkt. Of je nu een spss analyse uitvoert of regressie analyse in Excel of software zoals R, Stata of Python: de logica en stappen blijven hetzelfde. Met onderstaand stappenplan werk je van ruwe data naar betrouwbare conclusies, inclusief het controleren van kwaliteit en het toetsen van assumpties regressie analyse.
Data voorbereiden
Verzamel je data en controleer of variabelen correct zijn ingevoerd, zodat het analyseren van gegevens op een betrouwbare manier kan plaatsvinden. Verwijder dubbelen, controleer missende waarden en bepaal hoe je daarmee omgaat. Maak indien nodig nieuwe variabelen, zoals een dummyvariabele (0/1) of een samengestelde score. Bekijk ook alvast basisstatistieken en een paar grafieken om vreemde patronen te zien.
Model opbouwen
Formuleer de onderzoeksvraag en bepaal welke variabele verklaard moet worden (afhankelijke variabele) en welke factoren mogelijk invloed hebben (onafhankelijke variabelen). In de opbouw van een onderzoeksverslag hoort vervolgens een onderbouwde keuze voor het juiste type regressieanalyse, zoals lineaire regressie bij een continue uitkomst of logistische regressie bij een ja/nee-uitkomst.
Parameters berekenen
Laat het programma de regressie schatten. Je krijgt onder andere regressiecoëfficiënten (effectgrootte), standaardfouten en p-waarden. Bij meervoudige regressie analyse interpreteer je coëfficiënten als het effect van één variabele terwijl je de andere constant houdt.
Resultaten controleren
Beoordeel de modelkwaliteit: past het model goed bij de data? Kijk naar verklaringskracht (zoals R-kwadraat bij lineaire modellen), significantie, en of de richting en grootte van effecten logisch zijn. Controleer ook of outliers of invloedrijke punten je uitkomst sterk bepalen.
Assumpties testen
Toets de assumpties regressie analyse, zoals lineariteit, onafhankelijkheid, normaliteit van residuen en (homo)scedasticiteit. Bij problemen kun je variabelen transformeren, een ander model kiezen of robuustere methoden gebruiken. Zo voorkom je conclusies die statistisch wankel zijn.
Het interpreteren van de resultaten van een regressie analyse draait om het begrijpen van wat het model werkelijk zegt over de data. Je begint met de regressiecoëfficiënten. Deze geven aan hoe sterk en in welke richting een onafhankelijke variabele samenhangt met de afhankelijke variabele, terwijl andere variabelen constant worden gehouden.
Vervolgens kijk je naar de significantie. P-waarden laten zien of een gevonden effect waarschijnlijk toeval is of statistisch onderbouwd. Daarnaast is de verklaringskracht belangrijk. Bij lineaire regressie analyse geeft de R-kwadraat aan welk deel van de variatie in de afhankelijke variabele door het model wordt verklaard.
Het rapporteren van een regressieanalyse vraagt om helderheid, structuur en transparantie. Start vanuit het onderzoeksvoorstel: beschrijf kort de onderzoeksvraag en motiveer waarom regressieanalyse passend is. Licht daarna het gekozen model toe, inclusief het type regressie, de afhankelijke variabele en de onafhankelijke variabelen.
Vervolgens worden de resultaten gepresenteerd: regressiecoëfficiënten, significantieniveaus en maatstaven zoals R-kwadraat of odds ratio’s. Zet deze niet alleen in tabellen, maar interpreteer ze ook in woorden, gekoppeld aan de onderzoeksvraag.
Bij het uitvoeren van een regressie analyse maken studenten vaak dezelfde fouten, vooral door onjuiste aannames of een verkeerde interpretatie van resultaten. Deze fouten kunnen leiden tot onbetrouwbare conclusies bij regressieanalyses, ook als de berekeningen technisch correct zijn. In de tabel hieronder zie je de meest voorkomende valkuilen bij regressie analyse en hoe je ze voorkomt.
| Veelgemaakte fout | Wat gaat er mis | Hoe voorkom je dit |
|---|---|---|
| Assumpties negeren | De assumpties regressie analyse worden niet gecontroleerd, waardoor resultaten vertekend kunnen zijn | Test altijd lineariteit, normaliteit, (homo)scedasticiteit en onafhankelijkheid |
| Correlatie verwarren met causaliteit | Een statistisch verband wordt onterecht als oorzaak-gevolg relatie geïnterpreteerd | Onderbouw causaliteit met theorie en onderzoeksopzet |
| Verkeerde variabelen kiezen | Belangrijke verklarende variabelen ontbreken of irrelevante variabelen worden toegevoegd | Baseer variabelenselectie op literatuur en hypothesen |
| Multicollineariteit negeren | Sterk samenhangende variabelen maken coëfficiënten instabiel | Controleer correlaties en VIF-waarden |
| Outliers negeren | Extreme waarden beïnvloeden de regressie onevenredig sterk | Detecteer outliers en beoordeel hun invloed bewust |
Heb je scriptiehulp nodig bij statistiek of regressie analyse tijdens het schrijven van je scriptie? Onze ervaren ghostwriters ondersteunen studenten die nadenken over het uitbesteden van je scriptie met jarenlange academische expertise in kwantitatief onderzoek en statistische methoden. Zij begrijpen hoe regressie analyse correct wordt toegepast, geïnterpreteerd en gerapporteerd volgens universitaire richtlijnen. Met professionele ondersteuning, zoals scriptie schrijven tegen betaling, werk je nauwkeurig, inhoudelijk sterk en met vertrouwen aan een scriptie die voldoet aan academische standaarden.